X-ray material segmentation using UNet and VGGNet
Introduction
Image segmentation is a crucial task in computer vision, particularly for medical applications and industrial automation. This post breaks down two highly effective Convolutional Neural Network (CNN) architectures, UNet and VGGNet, used for pixel-level material classification.
- The Goal: To understand the structural differences between these models and evaluate their trade-offs in terms of accuracy, computational overhead, and suitability for real-world industrial datasets.
- What you will learn: The encoder-decoder principle of UNet, the transfer learning potential of VGGNet, and how to choose the right model for your segmentation problem.
1. The Segmentation Problem
Pixel-level classification, or segmentation, requires not just classifying an image, but classifying every pixel in the image (e.g., identifying “metal” vs. “plastic”). This demands an architecture that can capture both high-level semantic information (context) and low-level spatial information (boundaries).
In our study, we addressed the challenge of analyzing tomographic X-ray data sets from synchrotron sources. While manual segmentation is labor-intensive and error-prone, deep learning offers an automated solution. The models were tested on two specific industrial cases:
- Dataset 1 (SOC): 500 images of nickel-yttria stabilized zirconia fuel electrodes.
- Dataset 2 (Battery): 16 images of a battery electrode from the ESRF synchrotron.
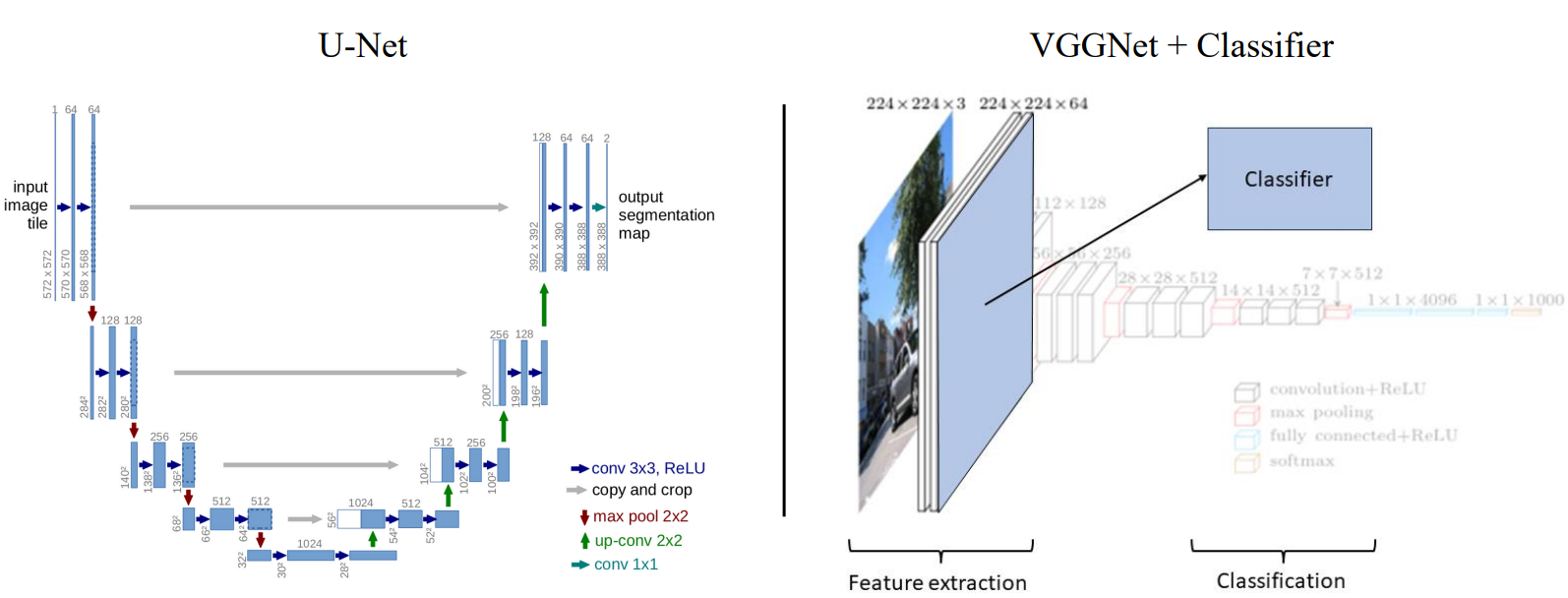
2. Architecture Breakdown: UNet vs. VGGNet
A. UNet: The Encoder-Decoder Powerhouse
- Concept: UNet uses a contracting path (encoder) to capture context and a symmetric expanding path (decoder) for precise localization.
- Key Feature: Skip Connections. These connections concatenate feature maps from the encoder to the decoder, preventing the loss of fine-grained spatial information during upsampling, critical for accurate boundaries.
- When to Use: Ideal for tasks requiring high boundary precision. On the SOC dataset, it achieved an F1-score of 97.43%. However, its generalization to the unseen battery dataset was lower (82.73%).
B. VGGNet (as a Feature Extractor)
- Concept: While VGGNet is a classification network, its powerful, pre-trained convolutional layers can be used as a robust feature extractor for a segmentation head.
- Key Feature: By leveraging pre-trained weights from the ImageNet dataset (14 million images), we can generate rich 64-dimensional feature vectors for every pixel.
- When to Use: Excellent for rapid prototyping or when generalization is key. The VGG-Net + NN model outperformed UNet on the unseen battery electrode dataset with an F1-score of 91.12%.
3. Practical Trade-offs in Implementation
| Metric | UNet Advantage | VGGNet Advantage (as Extractor) |
|---|---|---|
| Parameter Count | Lower (Approx. 18 layers) | Higher (Deeper model) |
| Speed/Efficiency | Faster inference | Slower inference |
| Data Requirements | Performs well with specific data | Excellent for transfer learning |
| Boundary Precision | Superior (due to skip connections) | Often less precise (information loss) |
4. Conclusion & Future Work
Both UNet and VGGNet offer powerful approaches to material segmentation, but their use cases diverge based on project constraints.
The Takeaway: If boundary precision and computational efficiency are paramount (typical in production environments), UNet is the clear choice. If leveraging a pre-trained model for quick results on a feature-rich task is the goal, VGGNet’s feature extraction capabilities shine.
